The High Frontier
Lately I’ve been reading about the prospects for space colonization. My interest was sparked by playing Kerbal Space Program[1], and stoked by reading Gerard K. O’Neill’s book The High Frontier[2]. The High Frontier was written in the 1970s, and is showing its age, but describes a compelling vision for human colonization of space.
The High Frontier got one big thing wrong: the space shuttle program ended up being 10-50x more expensive per launch than expected. His proposed roadmap involves launching from Earth’s surface the components for a large mass driver[3] to be placed on the moon, which is impractically expensive without lower launch costs. From a modern perspective, there are more appealing routes to bootstrapping manufacturing in space.
Origin of elements
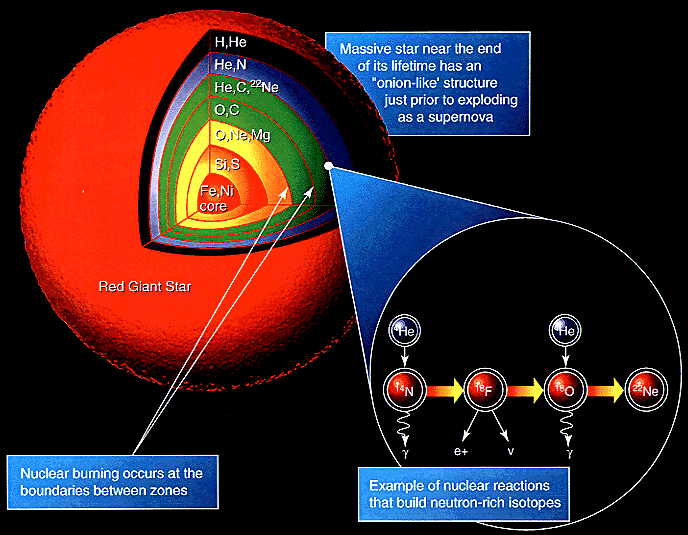
Stellar nucleosynthesis
Taking a step back, all of the heavy elements that are present on Earth came from stars. Smaller stars (like ours, Sol) fuse hydrogen into helium, with a small amount of carbon, nitrogen, and oxygen produced. A larger star starts with the same reactions, but has enough gravity to ignite further fusion reactions through higher pressure.[4] The heaviest element this produces is iron, which is the tipping point where fusion consumes energy rather than releasing it.[5] Because fusion of heavier elements doesn’t release energy to resist gravitational compression, a star that is massive enough to fuse iron into heavier elements will eventually collapse as a supernova.[6]
Earth, and our solar system, is formed from the debris of dead stars. But virtually all of the heavy elements Earth is formed from have ended up in the core of the planet; the heavy elements we find in the crust primarily come from asteroid impacts.
Asteroids
Earth is constantly bombarded by small asteroids; too small to see from the surface of Earth until they are heated by hitting the Earth’s atmosphere. Regularly, but on an astronomic timescale, a medium-sized asteroid will hit earth. The most famous evidence of this is the Chicxulub crater in Mexico.[7] That crater was made by a 10km asteroid that released energy equivalent to 4.7 trillion times the atomic bomb dropped on Nagasaki, and likely caused permanent climate change that led to the extinction of the dinosaurs.
Even a much smaller asteroid would destroy human society. But if we discover an asteroid on a collision course with Earth early enough, we can use a small amount of energy while it is far from Earth to avoid impact. We should not wait to discover such an asteroid to develop that capability.
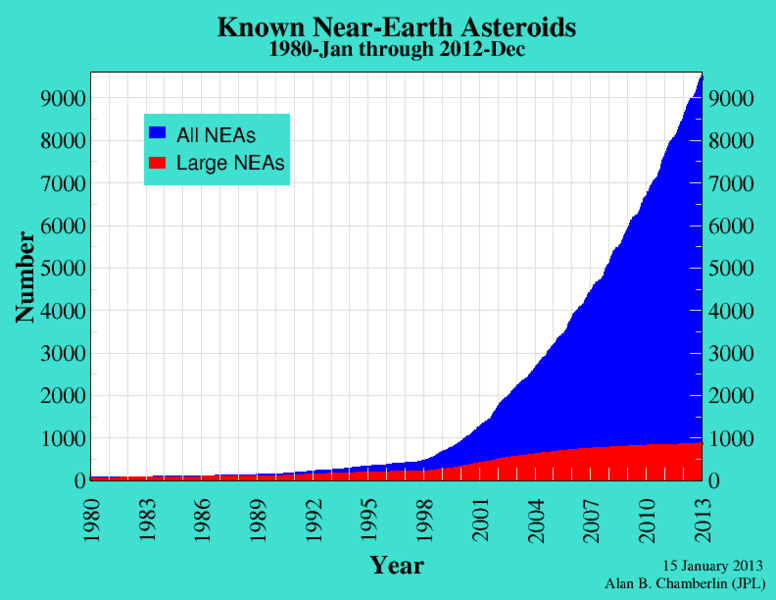
Near-Earth asteroids by time
Though the bulk of the asteroids in the solar system are in an orbit between Mars and Jupiter, some have an eccentric orbit that brings them in close to Earth’s orbit once for each revolution they make. These are called near-earth-asteroids; nearly all of them have been discovered since 1980, with more than 90% discovered since 2000.[8]
There are many different types of asteroids, but they come from the same dead stars as Earth, and as a whole, they contain the same elements as Earth. Most of them are small, but there are some exceptions. There are more than 800 near-earth asteroids with a diameter greater than 1km, with the largest having a diameter of 34km.[9]
Some of those 1km asteroids take less energy to reach than the moon, and have huge quantities of all the elements we need to bootstrap manufacturing in space: iron, silicon, carbon, nitrogen, hydrogen, oxygen. And those elements aren’t buried deep below a planetary crust at the bottom of a deep gravity well: a human on the surface of a 1km asteroid could reach escape velocity by jumping.
Manufacturing

Manufacturing a solar power array from asteroid materials
But instead of sending a human to tip-toe around an asteroid, we should send mining robots. Launching 1kg to low-earth orbit costs ~$10K[10], which is a double-edged sword: it means launching even a simple mining robot will be expensive; but it means that each kg that can be extracted and transported from the asteroid to low-earth-orbit is worth $10K.
Today, spacecraft must be launched from the surface with all of their fuel; if they were refueled in orbit, it would allow heavier, faster, or longer missions to be launched with our existing rockets. This would eliminate one huge barrier to manned missions to Mars and other planets, where an energy minimizing route would expose a human to a dangerous amount of cosmic radiation. Fuel can be extracted from asteroids by using solar power to heat rocks containing water ice, and electrolysis to separate the water into hydrogen and oxygen.
Mining fuel is a good first step to exploiting space resources, but asteroids can provide the raw material to manufacture anything we can make on Earth’s surface. Mining elements for transport to Earth’s surface wouldn’t initially compete with today’s mining industry, but the supply of raw minerals in asteroids dwarfs what is available on Earth. According to The High Frontier[2]:
Even if we were to excavate the entire land area of Earth to a depth of a half-mile, and to honeycomb the terrain to remove a tenth of all its total volume, we would obtain only 1 percent of the materials contained in just the three largest asteroids.
(Kindle location 984)
We’ve reached a point where providing an American standard of living to everybody on Earth would despoil the Earth, and yet many Americans are still materially poor. It’s necessary to limit consumption of Earth’s resources to a sustainable level, but that should not be seen as the limit for human society. In 50 years, I hope to see a decreasing number of humans on Earth, and a rapidly increasing number in space. We only have one planet that supports life, and we shouldn’t spoil it by living here.
Habitats
One of O’Neill’s engineering contributions was to show that it is possible, without exotic materials, to build large amounts of livable area in space. He proposed a 5 mile diameter steel cylinder, spinning at a rate that would produce centrifugal force equivalent to Earth gravity.[11] It would take a huge amount of energy to launch the material for such a structure from the surface of Earth, but there are enough raw materials in the asteroids to build many times the surface area of Earth in O’Neill cylinders.

Interior of an O’Neill cylinder
Even if you can build such a structure, there are a lot of engineering challenges to make it livable. You have access to as much solar power as you want, but you need to radiate the resulting heat. You would need to manage the carbon cycle, transferring CO2 from the breathable air to carefully controlled food growth capsules. All waste would be broken down into its constituent elements and recycled. But by solving those problems, you can make a habitat that is perfectly tuned for human life; perfect weather, long days, and fewer natural disasters.
Another advantage to life in artificial gravity is easy access to zero-g and space. Transportation between habitats could be at high speeds without losing energy to air resistance, lift, or rolling friction. Manufacturing would benefit from using space’s vacuum to produce ultra-pure materials, and the lower energy needed to move heavy objects in zero-g.
Mars and Luna
These advantages give orbital habitats a clear advantage over trying to colonize the surface of Mars, or other large bodies in the solar system. Space-based manufacturing will make it easier to get to Mars, but the energy required to escape a planetary surface makes it unappealing to settle at the bottom of the Mars gravity well after going to great effort to climb out of Earth’s. The surface of Mars may look familiar to us, but that is deceptive: the engineering and energy costs to colonizing the surface of Mars would be at least as high as building orbital habitats.

Lunar base with mass driver
In contrast to Mars, the moon has some advantages over even asteroids as a location for extracting resources; primarily that it is always close to Earth, and has easily accessible water in the perpetual shadowed craters near the poles.[12] However, it takes more energy to escape the surface of the moon, and lunar soil doesn’t contain the same diversity of elements that asteroids do. It’s only attractive as a stepping stone to the asteroids, but any manufacturing techniques developed for use in lunar gravity would likely be useless in zero-g and on asteroids. O’Neill’s plan for economical removal of material from the moon relied on building a huge mass driver[3], something that would take more than a decade of manufacturing build-up to create from lunar materials, or launching an impractical amount of material from Earth. In comparison, returning material from an asteroid requires potentially waiting several years for a good transfer opportunity, but then takes less overall energy than anything returned from the surface of the moon.
The seed
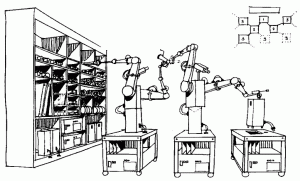
Self-assembling machine
There are a lot of details to work out, but the work done so far leaves little doubt that the problems can be solved. The first step is to build an automated manufacturing system that can use asteroid materials to self-replicate from a “seed” launched from Earth[13].
The cost to do this is primarily in engineering. Such a seed would likely need several generations of building progressively more specialized manufacturing systems before it could achieve “closure” by developing the capability to self-replicate. But it is not necessary to design all generations before deploying the seed; only to be confident that the seed is capable of closure in a reasonable amount of time. As the seed builds each new generation of capability, engineers on Earth can continue to work on the design of the following generations.
Once the seed is capable of self-replication, exponential growth could make more resources available in space than on Earth within several decades, and sustain that growth for a thousand years. With vastly more resources in space, would humans still prefer to live on hot, crowded Earth?
References
[1]Kerbal Space Program
[2]The High Frontier on Amazon
[3]Mass driver on Wikipedia
[4]Stellar nucleosynthesis on Wikipedia
[5]Iron peak on Wikipedia
[6]Supernova nucleosynthesis on Wikipedia
[7]Chicxulub crater on Wikipedia
[8]Near-Earth object on Wikipedia
[9]1036 Ganymed on Wikipedia
[10]Comparison of orbital launch systems on Wikipedia
[11]O’Neill cylinder on Wikipedia
[12]Lunar water on Wikipedia
[13]Advanced Automation for Space Missions NASA study
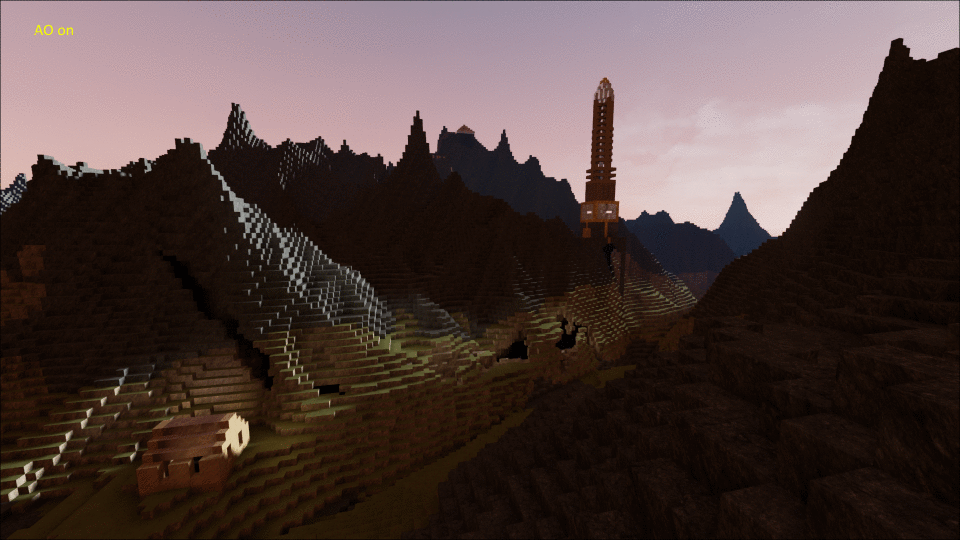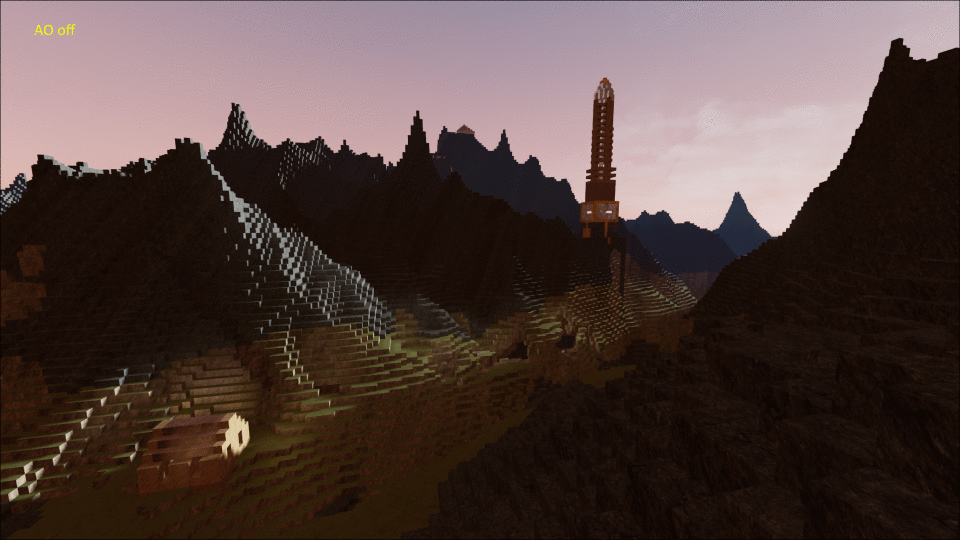
 I’m way behind on blogging about this, but in April 2014 I spent a month making a plugin for Unreal Engine 4 for rendering and interacting with Minecraft-style voxel worlds, along with a simple game called BrickGame to demonstrate it.
I’m way behind on blogging about this, but in April 2014 I spent a month making a plugin for Unreal Engine 4 for rendering and interacting with Minecraft-style voxel worlds, along with a simple game called BrickGame to demonstrate it.